Peut-on forcer ChatGPT à fournir ses sources ?

Dans un monde hyperconnecté où chaque clic révèle un océan d’informations, l’accès rapide et facile à une multitude de données transforme radicalement notre manière d’apprendre, de travailler et de prendre des décisions au quotidien. Dans ce contexte, l’exactitude, la fiabilité et la transparence de l’information sont non seulement des atouts, mais aussi des nécessités impérieuses. La prolifération des plateformes numériques et des réseaux sociaux a exacerbé le défi de discerner les faits de la fiction, rendant la question de la vérifiabilité des sources plus cruciale que jamais.
C’est dans cet environnement numérique complexe et saturé que les technologies d’intelligence artificielle (IA), telles que ChatGPT d’OpenAI, émergent comme des outils puissants, capables de synthétiser et de générer des informations à une vitesse et une échelle sans précédent.
Cependant, avec cette capacité remarquable vient une interrogation fondamentale sur la transparence et l’authenticité. Peut-on, et doit-on, exiger de ChatGPT et d’autres technologies similaires qu’ils révèlent leurs sources ? Cette question n’est pas seulement technique, mais profondément ancrée dans les principes éthiques qui devraient guider le développement et l’utilisation de l’IA. Explorer la réponse nécessite de plonger au cœur du fonctionnement de ChatGPT, de déchiffrer les mécanismes d’apprentissage qui alimentent son intelligence et d’évaluer les politiques d’OpenAI en matière de transparence et de responsabilité. En comprenant ces éléments, nous pouvons mieux saisir les possibilités et les limites de l’IA dans la quête d’une information fiable et vérifiée.
Comprendre le fonctionnement de ChatGPT
Au cœur de l’innovation en intelligence artificielle, ChatGPT, développé par OpenAI, se distingue comme une avancée significative dans le domaine du traitement automatique du langage naturel. Reposant sur le modèle GPT (Generative Pre-trained Transformer), ChatGPT a la capacité de comprendre et de générer du texte d’une manière qui simule étroitement le discours humain. Son entraînement sur un vaste ensemble de données textuelles lui permet de répondre à une variété de requêtes avec une précision remarquable.
Ce processus d’apprentissage, connu sous le nom d’apprentissage profond, permet au modèle de saisir les nuances de la langue, les contextes variés et même les subtilités de la communication interpersonnelle.
La particularité de ChatGPT réside dans son approche de l’apprentissage automatique, qui utilise des techniques d’apprentissage supervisé et non supervisé pour affiner ses réponses. À travers des itérations successives et une exposition à de nombreuses situations de dialogue, ChatGPT apprend à prédire la suite la plus probable d’un texte donné, ce qui lui permet de participer à des conversations fluides et pertinentes.
Peut-on demander à ChatGPT de citer ses sources d’information ?
La capacité de ChatGPT à générer des réponses cohérentes et apparemment réfléchies soulève naturellement la question de la vérifiabilité et de la transparence de ses informations. Dans un idéal de clarté et de responsabilité, il serait bénéfique de pouvoir exiger de ChatGPT qu’il cite ses sources.
Cependant, la réalité technique derrière le fonctionnement de ChatGPT complexifie cette demande. Étant donné que ChatGPT est entraîné sur un vaste corpus de textes provenant de l’internet, il n’enregistre pas les sources spécifiques de chaque fragment d’information qu’il a appris. Ainsi, quand ChatGPT génère une réponse, il le fait en se basant sur les modèles de langage qu’il a assimilés, sans pouvoir faire référence à une source unique ou vérifiable.
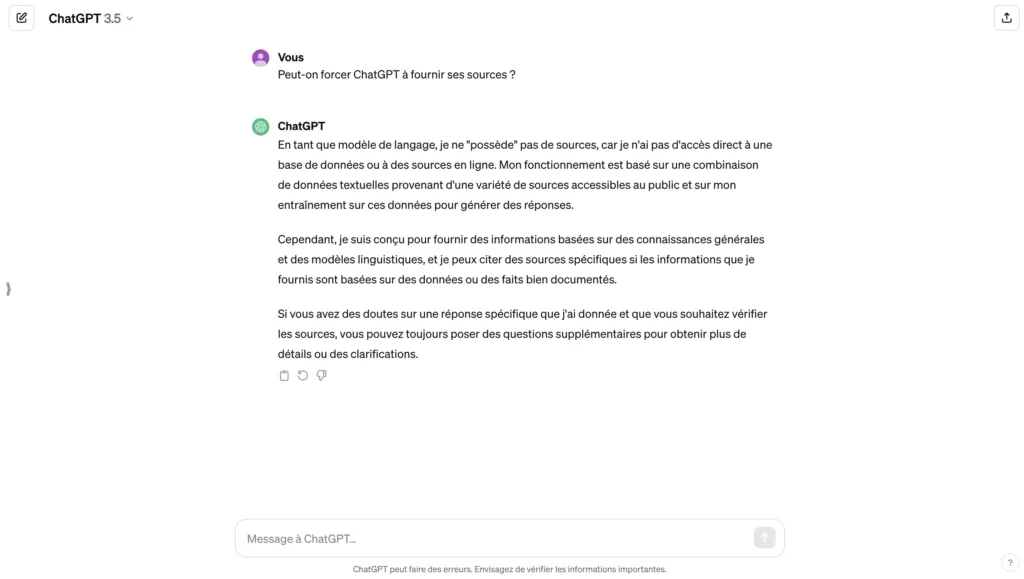
Néanmoins, il est possible d’encourager les pratiques qui augmentent la transparence de l’information générée par l’IA.
Par exemple, les développeurs et les utilisateurs peuvent travailler ensemble pour formuler des demandes qui orientent ChatGPT vers des réponses basées sur des données et des faits généralement reconnus et vérifiables par des moyens externes.
De plus, OpenAI s’efforce d’intégrer dans ChatGPT des mécanismes de réponse qui incluent, lorsque c’est possible, des indications sur la nature générale des sources d’informations (comme des études de recherche, des articles de presse, ou des bases de données académiques) sans pour autant pouvoir spécifier des sources précises.
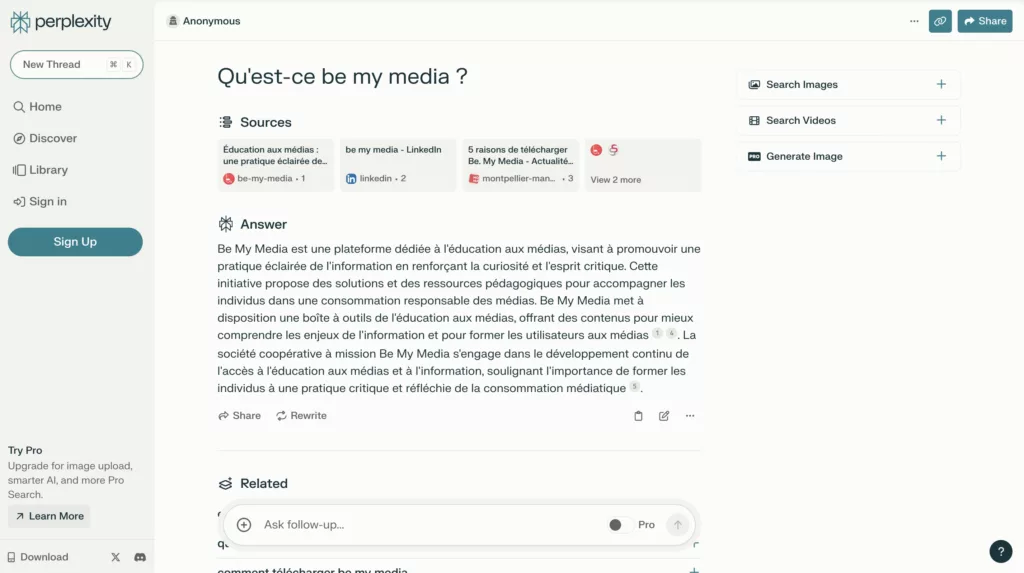
Des outils alternatifs tels que Perplexity citent leurs sources d’information.
Des outils alternatifs tels que Perplexity se distinguent par leur approche innovante en matière de transparence et de fiabilité des informations fournies. En effet, Perplexity AI met un point d’honneur à citer ses sources d’information, offrant ainsi aux utilisateurs un moyen vérifiable de tracer l’origine des données sur lesquelles se fondent ses réponses. Cette pratique contribue significativement à renforcer la confiance dans l’utilisation des technologies d’IA pour la recherche et l’analyse d’informations.
L’outil Claude représente également une avancée significative dans l’approche éthique de l’intelligence artificielle. Conçu pour rivaliser avec ChatGPT, Claude s’engage à respecter des standards éthiques élevés, offrant une option de choix pour ceux qui privilégient des technologies d’IA responsables et transparentes. Toutefois, il est à noter que Claude n’est pas encore disponible en Europe, ce qui restreint actuellement son accès à une audience globale. Ce développement souligne l’importance croissante des questions éthiques dans l’évolution de l’IA.
La question du modèle économique pour les médias et créateurs de contenus
L’intégration croissante de technologies telles que ChatGPT dans notre quotidien numérique pose un défi de taille pour les médias traditionnels et les créateurs de contenus. L’émergence de ces outils d’IA, capables de générer du contenu à une vitesse et un volume sans précédent, soulève des questions pertinentes concernant les droits d’auteur et le modèle économique sous-jacent à la création et à la diffusion de l’information. Un cas emblématique de cette tension est la poursuite judiciaire initiée par le « New York Times » contre ChatGPT et Microsoft, mettant en lumière les préoccupations autour de l’utilisation non autorisée de contenus protégés par des droits d’auteur pour entraîner des modèles d’IA.
Cette affaire judiciaire illustre le dilemme auquel sont confrontés les médias et les créateurs de contenus : comment protéger leur propriété intellectuelle et assurer la pérennité de leurs modèles économiques face à des technologies capables d’apprendre de leurs œuvres et de les reproduire sous une forme nouvelle ?
La question centrale réside dans la capacité des créateurs à maintenir le contrôle sur l’utilisation de leurs contenus, tout en naviguant dans un paysage numérique en constante évolution, où l’information et sa reproduction deviennent de plus en plus fluides.
La poursuite du New York Times contre ChatGPT et Microsoft souligne également le besoin urgent de cadres réglementaires adaptés, qui reconnaissent à la fois les avantages et les défis posés par l’IA dans le domaine de la création de contenus. Ces cadres devraient viser à équilibrer la protection des droits d’auteur avec la promotion de l’innovation et de l’accès à l’information. Ils devraient également tenir compte des spécificités de l’IA, notamment sa capacité à générer du contenu de manière autonome, en s’appuyant sur des données existantes.
Vers une réglementation européenne sur l’intelligence artificielle ?
Le cas récent de l’Italie, qui a pris la décision audacieuse d’interdire temporairement ChatGPT, met en lumière les préoccupations croissantes autour de la sécurité, de la confidentialité des données, et de l’impact sociétal de l’intelligence artificielle. Cette interdiction, motivée par des inquiétudes relatives à la gestion des données personnelles et à la diffusion de fausses informations, soulève des questions importantes sur la manière dont les sociétés choisissent de réguler les technologies d’IA.
Bien que cette mesure soit vue par certains comme un pas nécessaire pour protéger les citoyens, elle souligne également les limites d’une approche fragmentée et nationale face à une technologie qui transcende les frontières.
L’Union Européenne, consciente de ces défis, travaille activement sur le développement d’un cadre réglementaire global pour l’intelligence artificielle, connu sous le nom d’Acte sur l’Intelligence Artificielle (AI Act). Cette législation vise à établir des normes communes pour garantir que les systèmes d’IA soient utilisés de manière éthique, transparente et responsable dans l’ensemble de l’UE. L’objectif est de créer un environnement réglementaire qui encourage l’innovation tout en protégeant les droits fondamentaux des individus et en prévenant les abus potentiels.
L’esprit critique s’impose comme la compétence clé à développer
Dans le sillage des préoccupations soulevées par l’utilisation croissante de l’intelligence artificielle pour générer et diffuser des informations, l’importance de l’esprit critique n’a jamais été aussi cruciale. Face à un flot incessant de données, la capacité à évaluer de manière critique la fiabilité et la validité des informations devient une compétence indispensable pour les citoyens du 21e siècle. Cette compétence va au-delà de la simple capacité à distinguer le vrai du faux ; elle englobe la capacité à comprendre les nuances, à reconnaître les biais potentiels et à prendre des décisions éclairées basées sur une analyse rigoureuse des faits disponibles.
L’esprit critique permet aux individus de naviguer avec discernement dans l’océan d’informations générées non seulement par des humains mais aussi par des machines.
En développant une pensée critique affûtée, les utilisateurs peuvent mieux évaluer la pertinence et l’authenticité des contenus produits par des technologies telles que ChatGPT. Cette compétence devient un bouclier contre la désinformation et les fausses nouvelles, renforçant ainsi la résilience des sociétés face aux tentatives de manipulation et aux théories du complot.
Encourager le développement de l’esprit critique passe par une éducation qui met l’accent sur l’analyse, la réflexion et le questionnement. Les programmes scolaires, les initiatives de formation continue et les campagnes de sensibilisation doivent intégrer l’éducation aux médias et à l’information comme un pilier fondamental, préparant ainsi les citoyens à interagir de manière plus consciente et réfléchie avec les technologies d’IA. En outre, les plateformes et les développeurs d’IA, conscients de leur rôle dans la formation de l’opinion publique, ont la responsabilité de concevoir des technologies qui favorisent la transparence et encouragent l’engagement critique des utilisateurs.

Nous partageons tous les mois des contenus
pour décrypter le monde des médias et de l’information
Podcast, guides, outils, infographies, évènements… nous partageons chaque mois, nos meilleures ressources pour vous mieux comprendre et appréhender les enjeux médiatiques et informationnels.